How Netflix Autoscales CI
What does CI look like at Netflix
Jenkins @ Netflix
The Spinnaker view
Clusters and ASGs
How to plan for CI infrastructure
Infinite resources
Infinite Patience
Instant resources
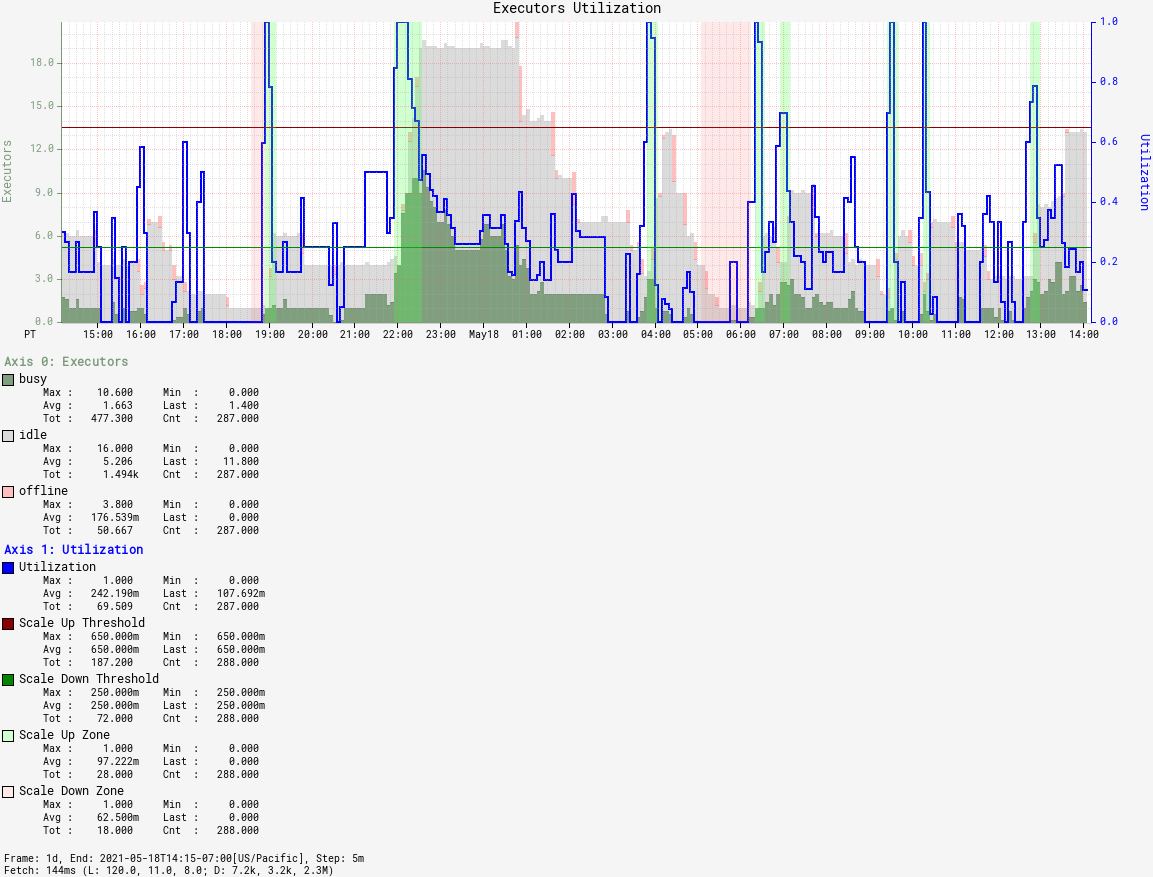
Autoscaling
What Metric to use
System Metrics
System Metrics
Queue Depth
Agent Utilization
Measuring Agent Utilization
An agent’s ASG
When launching agents, use labels to specify the placement of the agent.
Capturing Metrics
Autoscaling
How to Autoscale
When to scale up
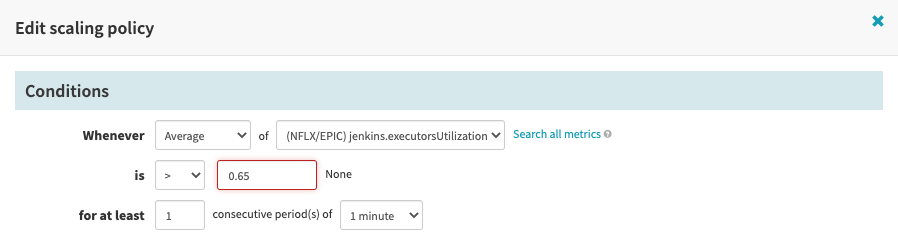
How to scale up
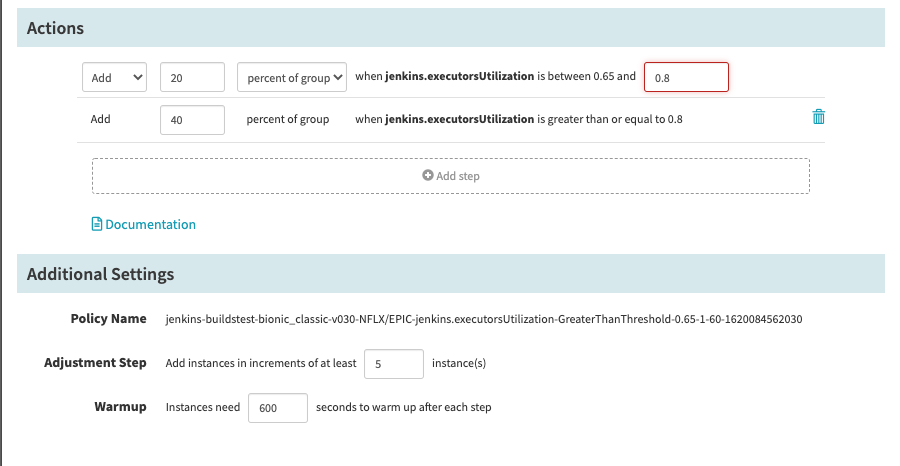
When to scale down
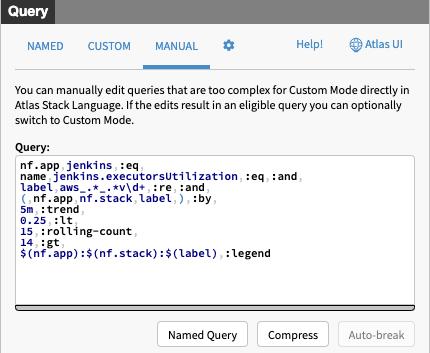
How to scale down
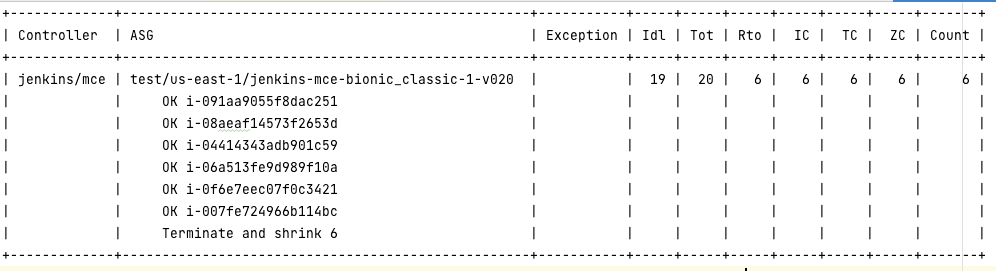
Recap